铁桶 (Message Wall | contribs) No edit summary Tag: Help |
m (+de) |
||
| Line 116: | Line 116: | ||
[[Category:Help]] |
[[Category:Help]] |
||
| + | |||
| + | [[de:Hilfe:Performance]] |
||
Revision as of 23:46, 5 February 2021
As the web (and the services and sites that support it) grows and changes, the technical portions of sites like Fandom must adapt to accommodate our users' habits and remain modern. For information services like wikis, there are infinite sources where fans can find answers about nearly any subject.
While we would love to imagine that fans instantly make their way to one Fandom community or another by typing in an obvious web address, the reality is that more than 80% of Fandom's incoming web travelers enter through search engine results.[1] In most of the world, Google provides a nearly exclusive platform for all search.[2] Additionally: most searches leading to Fandom wikis are not "X Wiki", but are more often searches for specific page titles and topics. This represents a change in user habits that has evolved with the web and the powerful impact of search engines.
Google frequently makes changes to the algorithms that power their search service, and occasionally signal the larger web about their intended plans. Three such changes[3][4][5] they have announced are expected to significantly impact Fandom in particular, due to the nature of how wikis develop and are edited. These changes, if not responded to, will lower the visibility of both individual wikis and the Fandom platform as a whole. Therefore, this guide will talk about how wikis are viewed from technical (and human) perspectives and what communities can do to make needed adjustments.
Measures
There are many factors that define a wiki's performance, and each step in the process has different measures.
MediaWiki performance
Before a wikitext page makes it to the web, that page has to become HTML. The parsing and "rendering" process takes place in the MediaWiki server software, where it is translated layer-by-layer into the basic language of web pages. The speed at which these are processed and served is usually done in under two seconds, and can be faster the second time the same unchanged page is served via a process called "caching".
MediaWiki page performance is measured in the time & memory resources taken to render the page, and also in how complex the HTML result is (because browsers must interpret the HTML code and turn it into something humans can understand visually). Pages that pull information from other parts of the server (a process called "transclusion") take more time and more resources. Using templates is a form of transclusion, so the complexity and nesting depth of templates affects performance. Dependent on how they are written, this can also apply to extensions that move content from one page to another (like DynamicPageList).

Core Web Vitals
Recently, Google pays attention to three key performance indicators that impact ranking. Collectively, these Core Web Vitals are:
- Largest Contentful Paint, or LCP, which measures loading performance, or how quickly the biggest content area of the page is visible to the reader.
- First Input Delay, or FID, which measures interactivity, or how quickly links or form elements can be tapped or clicked.
- Cumulative Layout Shift, or CLS, which measures visual stability, or how much the initially visible screen elements move before they can be interacted with.
")
")
")
Much of what is measured by Core Web Vitals is dependent on Fandom's distribution of wiki pages, though there are editor and community actions that can be taken to improve a wiki's vitals. While it is important to note these on desktop pages, most of Google's concern here is focused on (logged-out or anonymous) mobile views. For some purposes Google considers individual wikis when factoring ranking, but Google also considers the entirety of Fandom as one block in certain situations. Core Web Vitals has a larger effect on the platform as a whole (and therefore can lift smaller wikis that aren't as frequently searched for), but it is still important for individual wikis to be aware of them and potentially make changes.
Comprehensible content
More than simple metrics, having your wiki's pages well exposed and discoverable are important factors for performance.


{kind=link}
Important parts of Google's algorithm regards "Passage Ranking" and "total page indexing". Google touches every page it can find via links in pages and subtle maps and makes copies in its database, which it then processes to find information. That information includes Google reading sentences (from the index it created) and "understanding" their context — for example, if one page says (in a complete sentence) that "X is Y's mother" and another page says that "Z is X's father", Google effectively has a model in its "mind" that "Z is Y's grandfather" without that being explicitly written. This process of semantics helps Google to answer questions when users seek information. Where archaic search engine crawling was dependent on key words in a page, passage ranking is all about using natural language and exposed data (like tables and infoboxes) to develop models so that Google knows the right places to send seekers. In a sense, this is much like the old parable of "the blind men and an elephant"[6], where disparate pieces of information are used to craft a whole picture. This is why having more context and narrative (even if it produces longer pages) helps build a complete concept that Google can reference. It is not a coincidence that this method is also better for humans understanding wiki topics, because many of Google's methods are designed to mimic how humans think — if Google understands what a page is saying, it predicts that page will be the best resource for humans to understand that page (and others on the same wiki) and will rank such pages higher.
These comprehensive pages can be measured by how well filled they are. Having sparse pages with minimal reference content is more helpful to database-oriented websites than for Fandom wikis, where seekers are more interested in community voice and wisdom than simple facts. A community's expertise of when to split self-contained topics back out of longer articles or when to merge small related articles is an important measure that is not easily quantified.
User experience
Readers will not stay if they are driven away. Having pages that are overly dense with information or are hard to operate will drive information seekers to look elsewhere just as surely as badly written or low quality pages.
Google does measure the user experience systematically, in a number of ways. Objectively, Google can track the amount of time spent on a page and through analysis can build a model of how users experience the content within. Google also employs human Quality Raters to verify how effective the algorithm is in sending seekers to the right place. Those raters make professional opinions about how useful and usable a resource is, which can factor indirectly into rankings when Google's algorithm is adjusted based in part on their reports.
But the most effective measure of user experience starts with how easy or difficult it is to operate a web page — particularly if the content is easy to understand and interact with on mobile devices. All the fancy styling and gadgets added to a page can not overcome poorly organized or written material; such glitz may in fact make the user experience much worse if they seek specific knowledge and can't get through a page's frippery or hidden panels to find it.
Practical adjustments
There are practical ways to improve the performance of a wiki as editors. Many of these are habits to reconsider, in part because the nature of the web has changed from when wikis were first introduced. Each of these individually has small effects, but collectively they work to better position a wiki for better performance.
Original page content and stubs
While there are MediaWiki tools to automate and interpret the technical aspects of pages, like the length and interlinkages, those tools do not identify stubs or shallow content. Stubs are a traditional wiki term for pages that are manually marked as incomplete and needing more information to be added. Shallow content is that which does not answer the questions of an information seeker. Therefore, most stubs are also considered shallow content, even if not all short pages are stubs. Fandom wikis are not currently penalized for having an abundance of shallow content, though there is evidence that the Google algorithm makes assumptions about a wiki (or all of Fandom) when it encounters patterns of shallow content and may act accordingly in the future.
Short pages suffer from vitals issues, but stubs additionally have comprehension and user experience issues. For example, short pages have small content areas; sometimes these are small enough that the headers and toolbars become the largest page areas. As a result, the small content areas are relatively displaced more by things like toolbars and have high (and therefore bad) CLS scores. Because of their interactive natures, headers and toolbars are slower to load than content; if they are the largest page content (by HTML size, not visual real estate) and take longest to load, the LCP and FID scores will be less-than-ideal.
Stubs, because they don't answer deeper inquiries due to their shallow nature, tend to rank poorly with Google. Having a significant ratio of stubs to complete articles will lower the overall confidence Google has in the capacity of a wiki to answer subject matter questions and may therefore lower the ranking of pages on the same wiki (even if those pages are not stubs). Therefore, it is better to eliminate stubs as quickly as possible (sooner than 30 days, when Google may be expected to periodically re-index a wiki) by deleting the page, filling it out comprehensively, or merging it into a related page. It may help to remember that humans generally think the same way, and prefer seeing small information as part of a "bigger picture" rather than being incomplete and isolated. Having empty page sections, especially empty introductory sections (also known as "ledes"), has a negative effect on both the Google parser and the human user experience because such emptiness represents a dead-end rather than an opportunity.
Redlinks (or links to non-existent placeholders where pages should be) used to be seen as opportunities for editors and would-be editors to build new content pages. While there is some inquiry as to how effective redlinks are in attracting editing, redlinks are damaging to web vitals and search crawling; this is why redlinks are shown as plain text on the logged-out, mobile experience. Redlinks drive search engine crawlers to non-existent areas, effectively counting them as errors when a page can not be found. The total error count encountered on a website, wiki or not, lowers its perceived credibility and reliability. Reducing your overall number of redlinks quickly will help page performance and ranking.
Category pages are often an afterthought for wikis. They rank as highly as article pages if Google's model suggests that they should, due to inferred information. When they have no ledes or context, they appear on Google's result pages as garbled text. Each Category should have at least some text in the content area of the page.
Robust pages and mobile usability
A fairly misunderstood division of content is when articles are divided into tabbed segments (via links along the top of a page or interactive tabs). When these link to other pages — a process Fandom refers to as navigating with page tabs — they inherently create or imply incomplete concepts. Spreading the information needed to understand what is generally a single article concept (character, episode, weapon, etc.; otherwise known as a content entity) broken into multiple pages makes it more difficult for Google to create a model of that concept. In a similar way, human readers are less likely to want to visit and read through multiple pages to understand individual facets of the same item. This effect is sometimes referred to as "our princess is in another castle", because the seeker must travel through different links to find what they are looking for, following the scent of information on a chase to what they really want to know.
Having a "complete picture" where a seeker expects to find it and having a deeper or longer explanation of a single aspect on a separate page is not a bad thing. An "overview" page (typically called a "base page" because of its title without subpages) should contain at least the essentials needed to understand the article's concept. Links in the text body (perhaps using {{Main}} or {{See also}} templates under section headers) can lead the seeker to the deeper and more detailed information they wanted, especially when paired with a summary and an explanation of context. For example, on a page with "Biography" and "History" links at the top, how would a seeker know what information is on each page? This way, all articles involved can and should be complete thoughts in their own right and not fragments to be collected.
It should also be noted that if such page tabs are created with templates or JavaScript for a desktop-focused layout, they will not operate or appear properly on mobile devices. Such links will also not have any relevance to Google as semantic aides (the context is not understood and they just look like orphan links adrift at the top of the article's text). Rather than add something that either doesn't look and function well or doesn't appear at all for most readers, placing navigational links in a <navigation> segment of an infobox will produce a bridge that mobile users and search engines can both readily understand.

In this model, there is little distinction between "tab-shaped links" at the top of a page and icon-shaped links or indicators (commonly called EraIcons) somewhere else on the page (including the header). Both forms are difficult to see or operate on mobile devices, and the suggested move to infobox navigation applies to both.
No single block element (as in: not text) is as important as an infobox to an article. In a sense, along with an introductory (or "lede") section, infoboxes provide context and data points about an article's subject. As such, they are given special treatment on the mobile skin and have strong signals to Google. Their prominent position makes them ideal for navigation and interlinkage to other strongly related pages.
One issue with sections and pages that contain images, tables, and galleries is that there is often no narrative "anchor" to put the figure into context. This is for both semantic purposes (so that Google understands what the relationship is between the model it creates for the page and the figure or table indicated) and accessibility purposes (so that screen readers and other assistive devices can present a hint if the information is relevant or not before the table or figure is interpreted). Ideally, all images would have captions (text that puts the image into perspective for the article; e.g. "Batman, circa 2020") and / or alternative text (which literally describes the image for those that can't see it; e.g. "A costumed character brooding on a night-time rooftop" ). Put another way: alt-text explains what something is, a caption helps explain why it's there. For large galleries of images that can be logically grouped, it is better for both rendering performance and human understanding to divide these into smaller galleries. Ideal is interleaving such images with the narrative text so that text and image complement each other; such layouts work well on all devices.
Shortening pages
There is nothing inherently wrong with long pages (from a search engine's perspective). As noted above, these are more likely to be interpreted as complete content models with Google's passage ranking because the entire page is analyzed. If the content within is well organized, the reader's attention should have plenty to inform and entertain them without specific points being difficult to find.
However, it should be noted that placing blocks of content in interactive tab blocks (often called "tabbers") presents technical obstacles. Editing blocks of wikitext that are inside complex code (paragraphs inside a parser function) is more difficult with the Visual Editor interface used by most editors, and also makes editing with the wikitext editing interface harder to identify where elements begin and end. The layer of interactive JavaScript increases the FID vital score because of the need to render elements; if the tabber is in the initially visible area of the page when it first loads, it will also increase the CLS vital score because of what it is displacing. The tab actions themselves that reveal content may not operate properly on mobile devices at all. Mixed reports from the web indicate that content hidden inside a secondary tab may not be seen as important by Google.
Perhaps most important, though, is the user experience: content behind secondary tabs is "out of sight, out of mind" and is not as likely to be viewed by readers. Tabs beyond the first are accessed less frequently, with each additional tab more unlikely to be activated. Most of the time, readers don't even know that there is information not immediately visible to them, and will overlook what they are hunting for or enjoying because it is concealed from view.
For these reasons, employing tabbers to "shorten" pages is far from ideal for performance and experience in most cases. If tabbers must be used, usability guidelines from leading user experience experts suggest they must:
- not nest one inside another
- have tab labels only on one visual row
- use descriptive labels
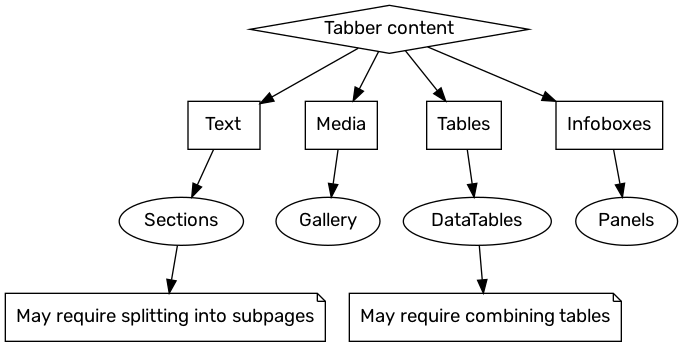
The inclusion of DataTables in that flowchart highlights a feature we would like to emphasize. Available soon from our Dev Wiki scripts, DataTables adds many new features to improve the long data table experience. Also worth noting is that using multiple infoboxes in a page is discouraged (for processing time and search engine parsing sake) and it is often more useful to consolidate multiple infoboxes (particularly those that share a lot of common properties) into a single infobox using the panel feature.
Main pages are special on wikis for a variety of reasons. For machines and for humans entering only the bare URL to a wiki (as opposed to a specific page), they represent the primary entry point from which linking spreads. Google interprets links on the main page (and the local navigation bar) as important places for understanding the wiki topic. As Google examines the wiki for the first time, not knowing anything else about the subject matter, it assumes all links have equal weight and importance. This is simple if there are 10 to 20 links to pages or categories. When widgets or panels add hundreds of links to the main page, the relative weight of those links approaches zero. As this document has alluded to many times, this is also the way humans tend to think: having too many choices results in "choice paralysis"; the effect is that they don't know where to start looking for true understanding.
Therefore, for technical and user experience reasons, we strongly suggest narrowing the links on a main page to those most important articles and categories needed for an understanding of the wiki's subject. We also suggest not using interactive widgets that drill down into lists of wiki pages as they impact render, vitals, and crawling performance. Assuming they are linked to by any other page, the crawler will get to them eventually. Also of note is that Google is instructed in most cases not to crawl Special or Talk pages, where they will initially may receive an error message or be redirected away. We suggest not linking to these from the main page (and in many cases these are linked to from the local navigation or Special:Community pages that are not immediately visible to Google).
There are many opportunities to include video into a wiki, but we suggest a maximum of two or three embedded video widgets. Both the performance impact and the visual impact of having more videos on a commonly loaded page limit the effectiveness of each video.
An evolving web
It's important to keep Google happy, because that's how we get visitors. But Google is based on human thought and habits, so what Google does is largely about making humans happy. These are not penalties Fandom is imposing on wikis. These are measures that keep individual wikis relevant in an evolving web.
- ↑ It is difficult to be more clear or emphasize enough how important Google has become in our global web: without Google, very few informational websites would be able to draw consistent traffic. It's not about ads, privacy, or social sharing. In a real sense, more than any single other web utility, Google Search brings order from chaos and powers the entire web.
- ↑ Google maintains a dominant position on search in all languages in nearly all countries except China’s mainland, Japan, Russia, South Korea, and Turkey. In most of those countries, Google still maintains either a supermajority of market share or is restricted by national governments. Though a user's personal preference may be Bing, Yahoo, Baidu, Yandex, or DuckDuckGo — these together do not represent more than 10% of all web search globally. Google is effectively the only external search engine significant to Fandom's web operations, and therefore the only one we are concerned in "keeping happy". Google's happiness extends as good practices for any other search engines, and providing better searcher experiences are ultimately better for our communities.
- ↑ Barry Schwartz, “Google: Mobile-First Indexing Should Be Mobile-Only Indexing,” Search Engine Roundtable (https://www.seroundtable.com/google-mobile-first-indexing-mobile-only-indexing-30270.html, n.d.)
- ↑ Roger Montti, “What Is Google Passage Ranking: 16 Key Points You Should Know,” Search Engine Journal (https://www.searchenginejournal.com/google-passage-ranking-martin-splitt/388206/, November 2020)
- ↑ Detlef Johnson, “Guide to Core Web Vitals for SEOs and Developers,” Search Engine Land (https://searchengineland.com/google-core-web-vitals-guide-for-seo-developers-337825, July 2020)
- ↑ "Blind men and an elephant" parable (Image “Blind Men and an Elephant,” 1907.)
{kind=link}